
The Copilot: How AI Turns 2,100 Challenges Into the Right One for You
Article 3 of 3 — The AI Behind the Match
A Different Kind of AI Claim
Most products that describe themselves as 'AI-powered' are hoping you won't ask too many follow-up questions. The phrase has become a kind of ambient marketing, applied broadly to anything that involves a model or an algorithm, regardless of whether the AI is doing anything that actually makes the product better.
This article is going to do the opposite of that. We're going to explain what the Simulations AI Copilot does, why it's designed the way it is, and what that means for the quality of the results you get. Not to show off the engineering, but because if you're a program leader or instructor deciding whether to trust a tool with something as important as your training program, you deserve to know what it's actually doing.
The Setup: What the Copilot Is Working With
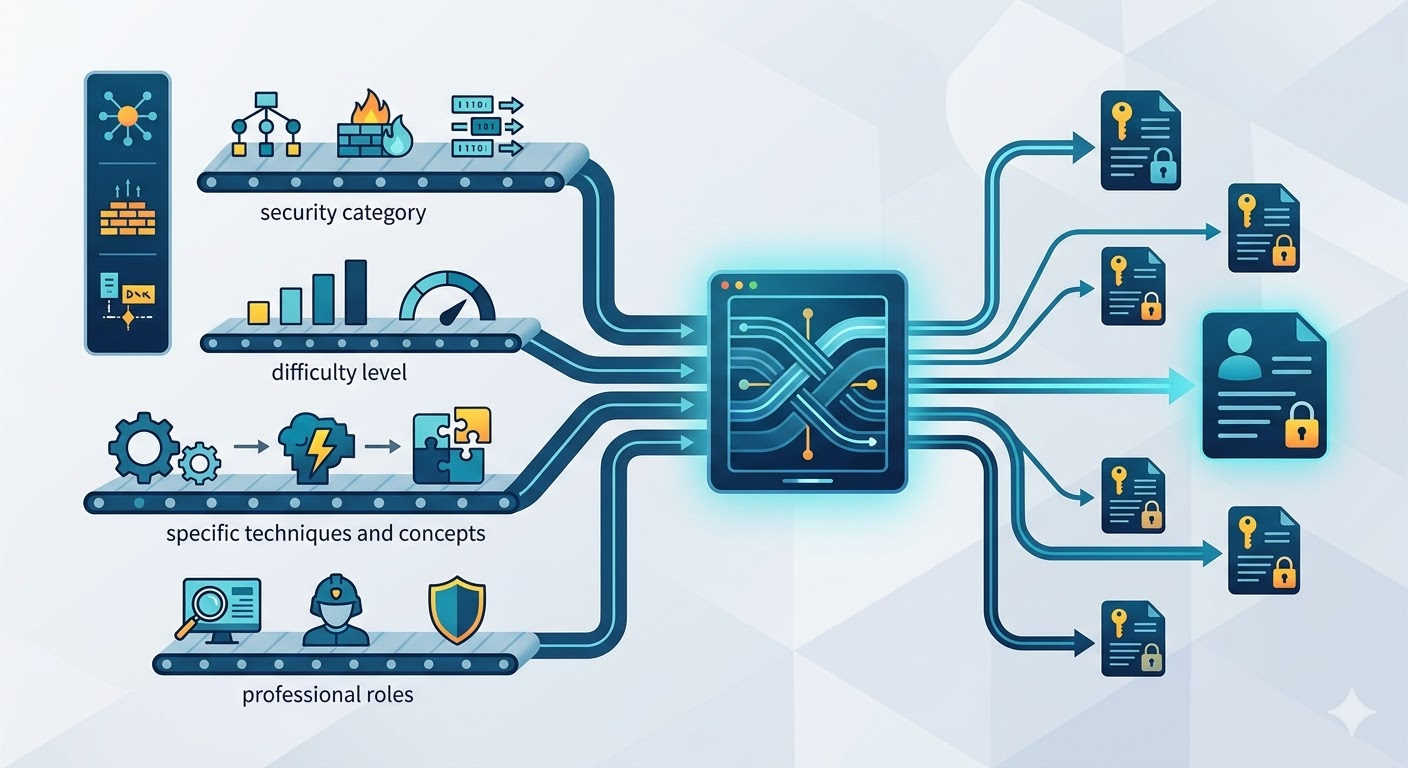
The Simulations Labs challenge library has over 2,100 scenarios. Each one carries a structured set of attributes — the security category it belongs to, the difficulty level, the specific techniques and concepts it tests, and the professional roles it's most relevant to. Some challenges are tagged to a single, focused skill. Others span multiple concepts and are relevant across several job functions.
This metadata is the foundation that the Copilot works from. It wasn't built for the AI — it was built because well-organized content is useful regardless of how you access it. The Copilot just makes that organization intelligently queryable.
From Natural Language to Structured Match
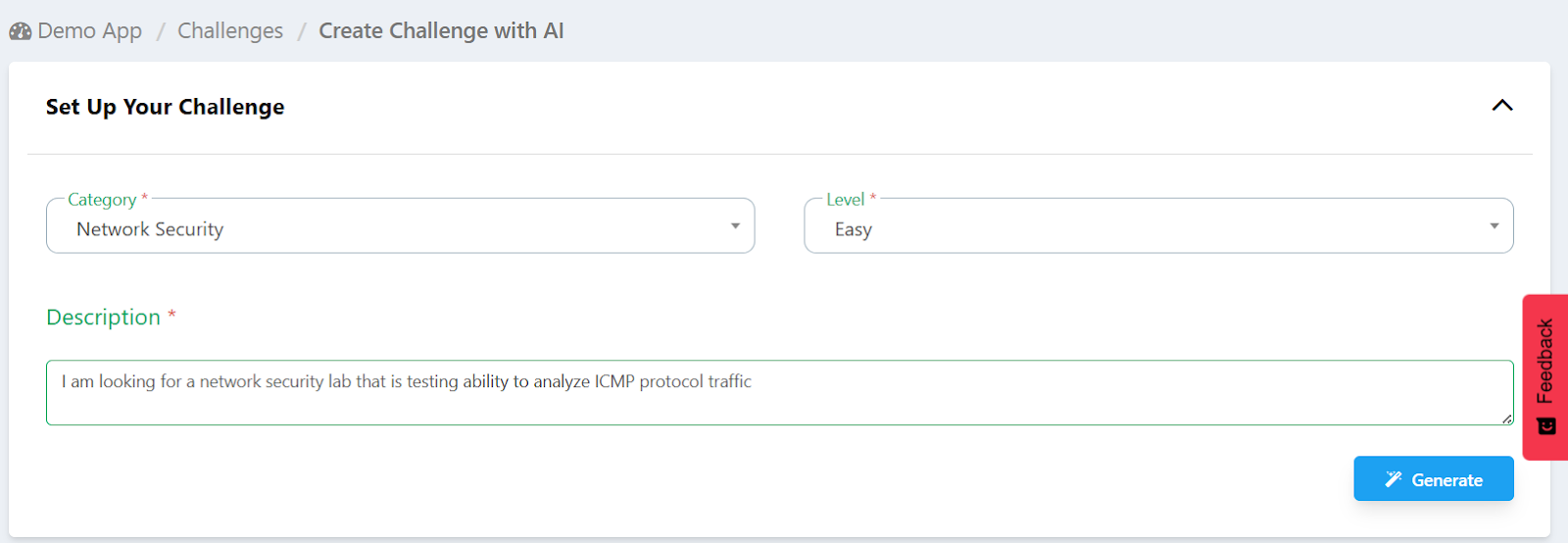
When someone uses the Simulations AI Copilot, they're not filling in a form with dropdown fields. They're describing what they need in plain language — the same way they'd explain a training goal to a colleague. That description might be specific ('I need a web security challenge on SQL injection, easy difficulty, for a junior analyst') or it might be general ('something that would work for a red team training day').
The Copilot's job is to interpret that description and translate it into meaningful search criteria against the library. This is where the AI layer matters. A standard keyword search would take the words in that description and look for matches. The Copilot takes the intent behind those words and maps it against what's actually available.
The distinction sounds subtle but it produces meaningfully different results. 'Something for a SOC analyst' doesn't mean 'anything tagged SOC' — it means challenges that genuinely develop the instincts and skills that SOC work requires. The model understands the language of cybersecurity professionally well enough to make that distinction.
How the Matching Score Is Built
Once the Copilot has extracted the relevant intent from a description — the topics, the role relevance, the difficulty range — it scores every challenge in the library against those criteria. This isn't a binary yes/no. It's a weighted relevance calculation.
A challenge that matches on both the specific topic and the job role scores higher than one that only matches on the topic. A challenge that hits the exact difficulty level scores higher than one at a difficulty that's adjacent but not quite right. Category alignment adds weight. And critically, the system doesn't just return everything that meets a threshold — it returns the top matches, ranked, so that the first result on the list is genuinely the closest fit to what was described.
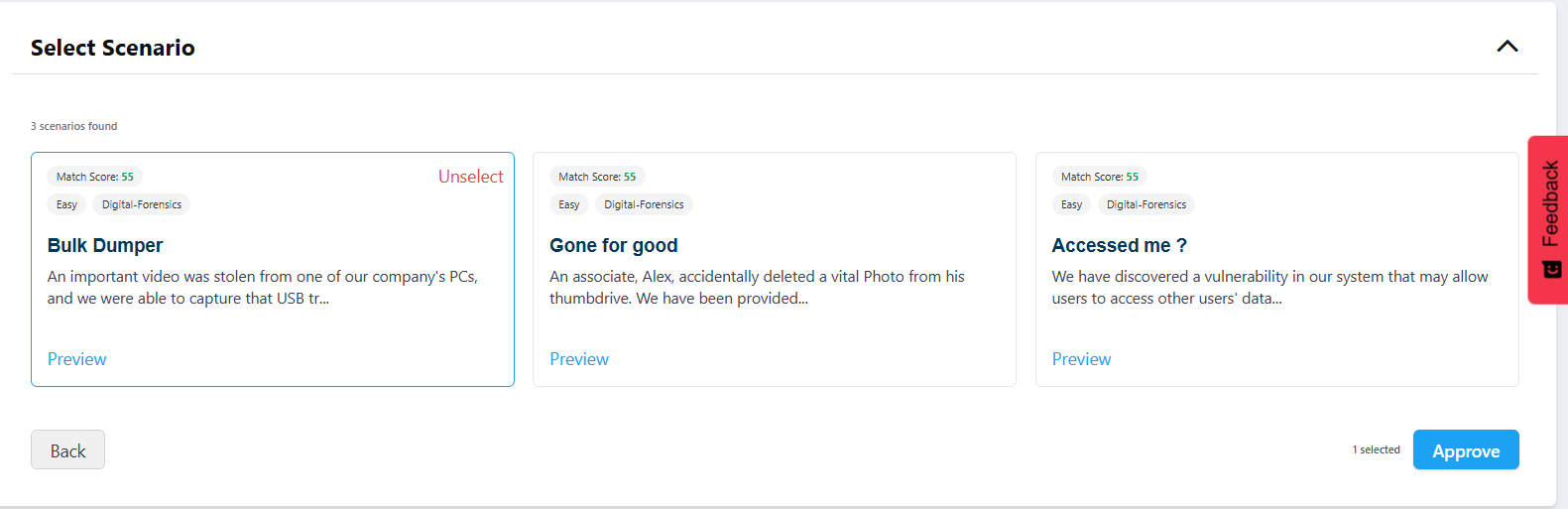
The ranked shortlist is the product. Not a long list of possibilities, not a raw dump of everything that technically qualifies. A curated set of the best matches, presented in order of relevance, with enough information visible — match score, tags, difficulty, a description preview — that the person evaluating them can make an informed final choice quickly.
Why the Metadata Quality Matters
AI matching is only as good as the data it works from. This is worth stating plainly, because it's a limitation that most AI-in-education tools don't acknowledge: if the underlying content is poorly categorized, the matching will be poor regardless of how good the model is.
The Simulations Labs library has been built and maintained by people who understand cybersecurity professionally. The tags and role mappings on each challenge reflect considered judgment, not automated labeling. When a challenge is tagged as relevant to a penetration testing engagement, that's because it genuinely is — not because a word in the title matched a tag in a taxonomy.
That quality of metadata is what makes the Copilot's matches trustworthy. The model is doing real interpretation work, but it's interpreting signals that were placed there carefully. The combination of good data and good matching is what produces results you can act on rather than results you have to second-guess.
The combination of good data and good matching is what produces results you can act on rather than results you have to second-guess.
The Three Steps in Practice
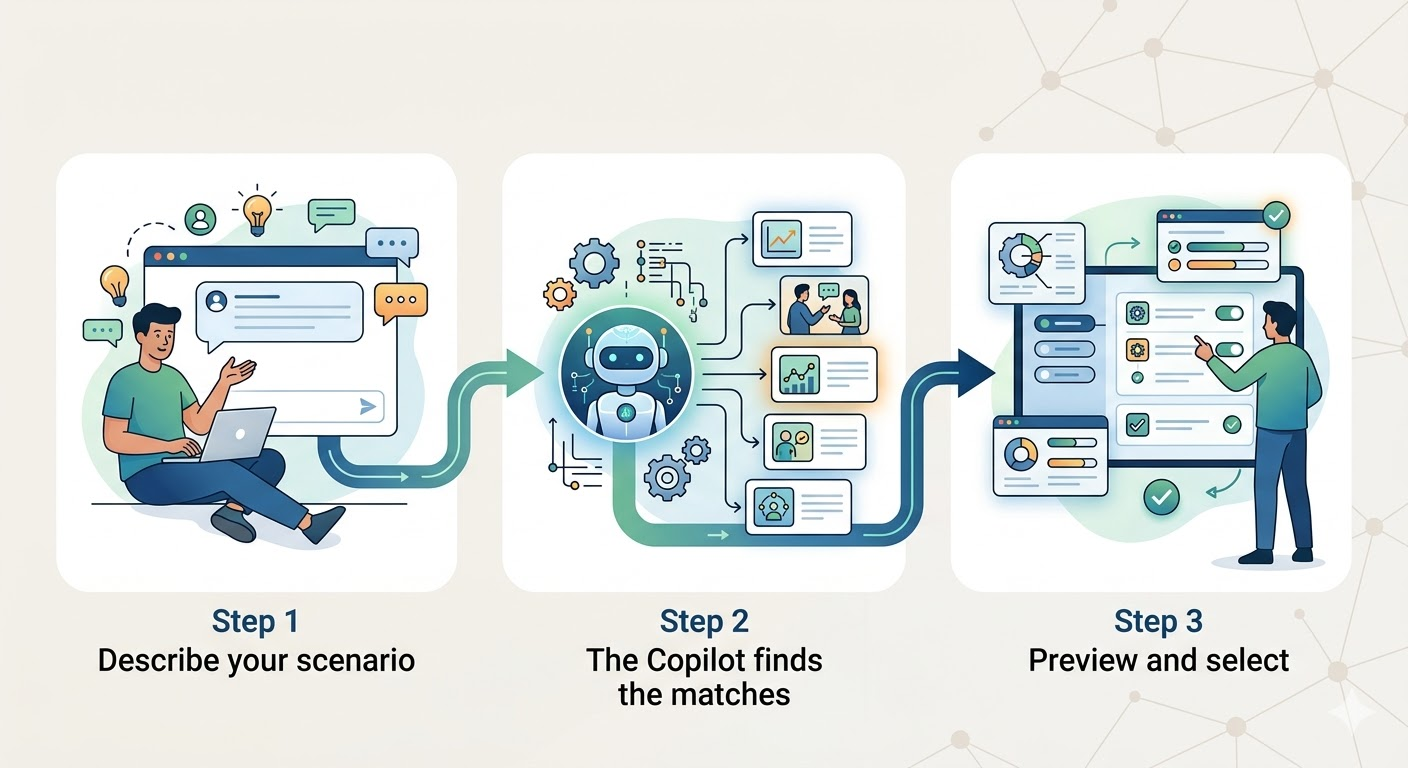
Step 1: Describe your scenario
You enter the details of the simulation you need — the topic, the skills you want to develop, the category, the difficulty, and the professional context. There's no required format. You write it the way you'd explain it to someone.
Step 2: The Copilot finds the matches
The AI reads your description, extracts the relevant intent, scores the library, and returns a ranked shortlist of the best-matching challenges — usually in a matter of seconds.
Step 3: Preview and select
You review the recommended simulations. Each one can be previewed in detail before you commit. When you've confirmed your selections, the challenges are created and ready to use in your event or training program.
What This Means for How Programs Get Built
The practical effect of the Simulations AI Copilot on how training programs are designed is not incremental. It changes the starting point.
Before, building a training program from a large library meant either knowing the library well enough to navigate it manually — which takes time and experience — or accepting that you'd use a limited subset of what was available because that's all you could find efficiently. Either way, the library was an asset you couldn't fully use.
With the Copilot, the library becomes fully accessible regardless of how familiar you are with its contents. A program leader can arrive with a training goal, describe it, and have a working shortlist of matched content in the time it would previously have taken to run the first few searches. The depth of the library — all 2,100 challenges, across every domain and difficulty — is usable from the moment you start.
That's not a productivity feature. It's a change in what's possible. Programs that would previously have required weeks of content curation can be assembled in an afternoon. Teams that didn't have dedicated instructional designers can build structured learning tracks. Organizations that wanted to start from the library but didn't know where to begin now have a tool that meets them exactly where they are.
Still Built for People, Not Instead of Them
The Simulations AI Copilot is a sophisticated tool. It's doing real work. But it's designed to serve the people running training programs, not to replace them. Every result it surfaces still goes through a human review. Every selection is a human decision. The expertise of the instructor — the understanding of their learners, their organizational context, their program goals — remains at the center of how training is built.
The Copilot just removes the part that didn't require expertise in the first place. The searching, the filtering, the time spent evaluating options that don't fit. That work is done. What remains is the work that only a skilled person can do.
Ten years of challenges. Built for your program, findable in seconds.


